Focusing on a single testimony from Boder’s archive, this project discusses the limits of topical indexing (the manifest, factual content of what was said) and shows how such indexing systems obscure what Primo Levi would later call “the gray zone” — namely, those spaces of complexity and ambiguity that blur moral clarity. In this project, we model two computational approaches to counter-indexing testimonies, both of which are text immanent, as they are derived directly from sets of words in the transcripts rather than from a secondary scaffolding meant to summarize experiences or enumerate keywords. The first approach uses n-grams to identify the frequency of recurring semantic phrases in the narrative; the second approach uses semantic triplets to index and visualize expressions of agency (reports of who did what to whom).
1. Boder’s indexing keywords
Developed by Lizhou Fan
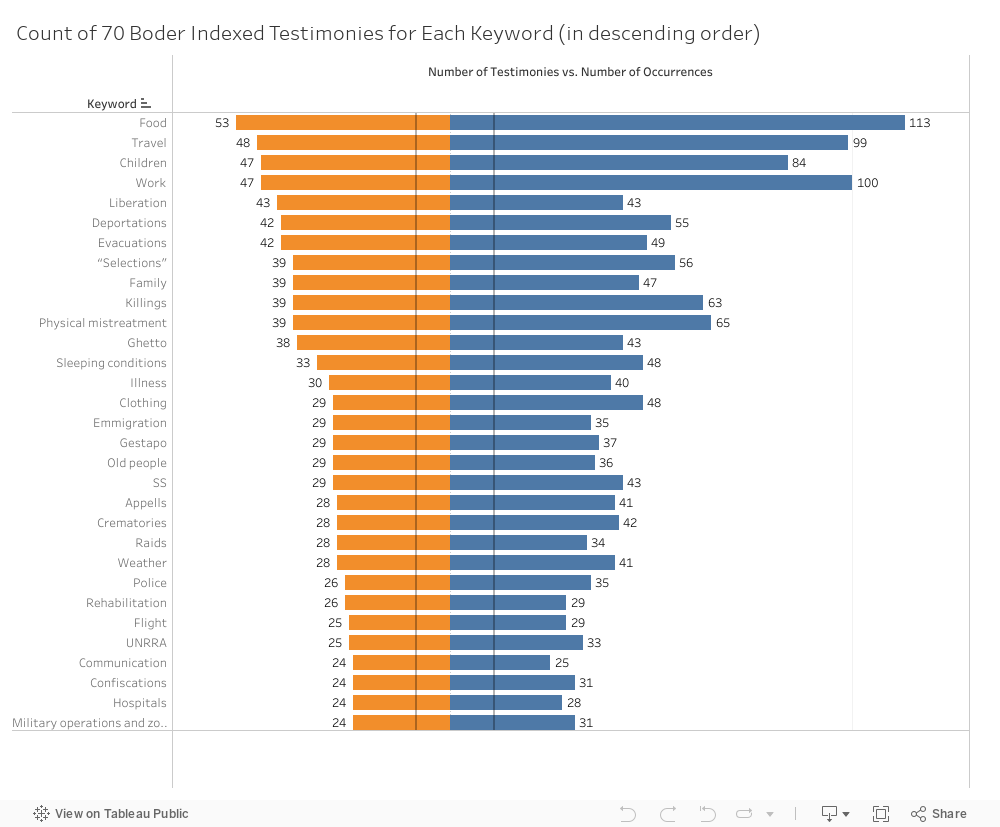
Frequency of Boder’s indexing keywords by number of testimonies and occurrences. Data source: David Boder, Topical Autobiographies (1957), UCLA Young Research Library Special Collections.
2. Keyword density in Boder’s 70 indexed testimonies
Developed by Lizhou Fan
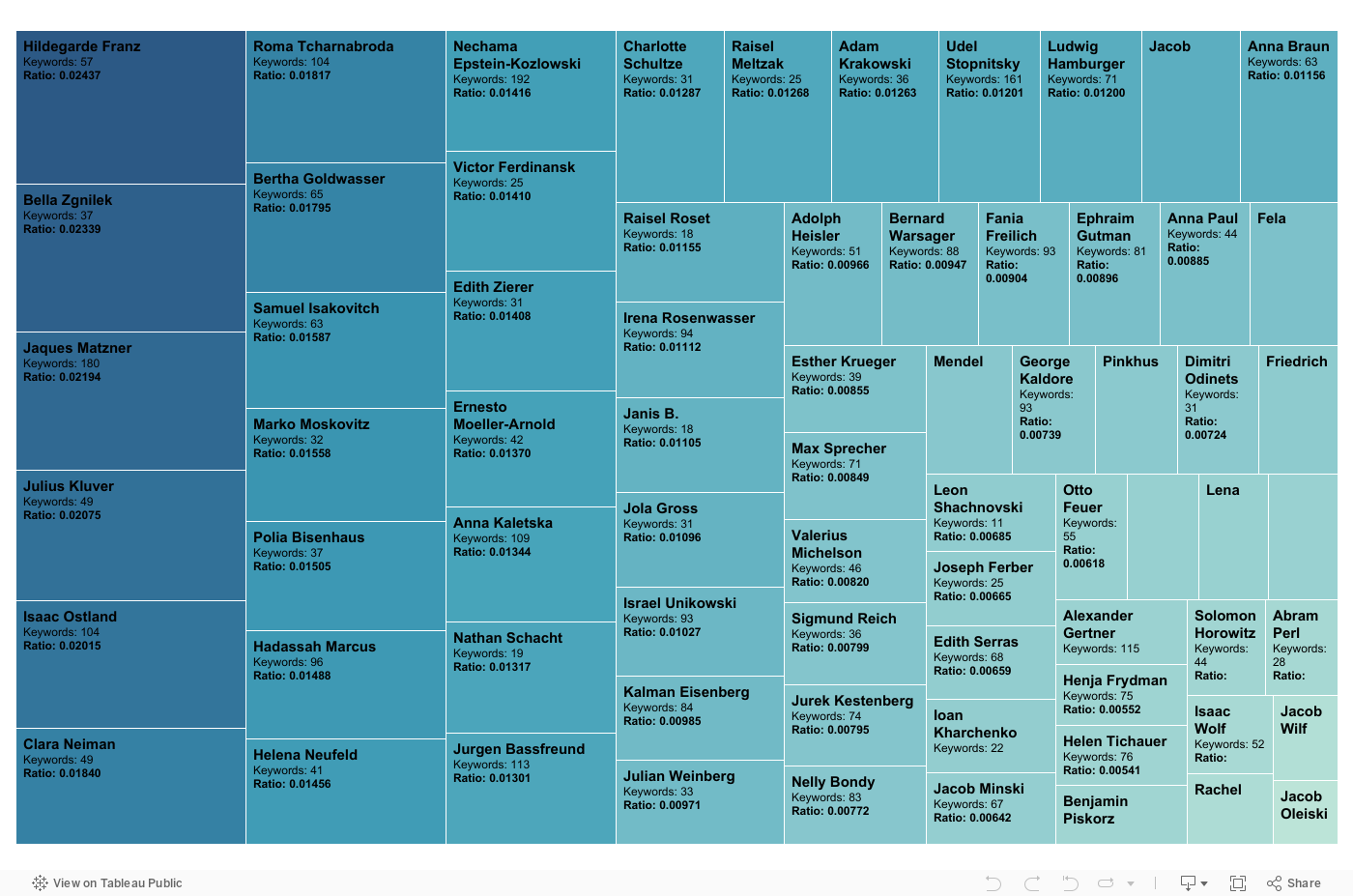
Indexing ratios for 70 interviews in Topical Autobiographies. Count is the number of indexing terms. The ratio is count divided by total words in the testimony. Data source: David Boder, Topical Autobiographies (1957), UCLA Young Research Library Special Collections.
3. Transcript of Boder’s interview with Abraham Kimmelmann
Developed by Anna Bonazzi
The original XML encoding was done by the Illinois Institute of Technology (Voices of the Holocaust, Paul V. Galvin Library), and we expanded it with additional mark-up detailing each line’s speaker, language, and speaking cadence (dialogue speed). The English translation was done by Boder and includes editing by the IIT team. To identify the different languages used across Boder’s corpus line-by-line, two Python packages were used: TextBlob for lines below 11 characters (high accuracy but daily usage limitations) and langdetect for all other lines (high accuracy but only on longer strings; no usage limitations). As Boder’s interviews are highly multilingual, it was important to label the languages used in every line.
4. Boder’s keyword-based indexing of Kimmelmann’s testimony
Developed by Anna Bonazzi
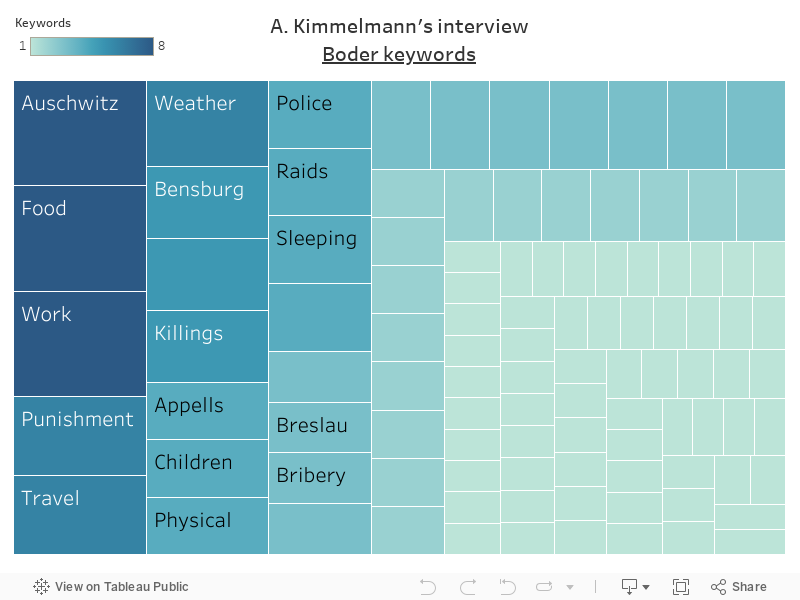
Data source: David Boder, Topical Autobiographies (1957), UCLA Young Research Library Special Collections.
5. N-gram-based indexing of Kimmelmann’s testimony
Developed by Anna Bonazzi
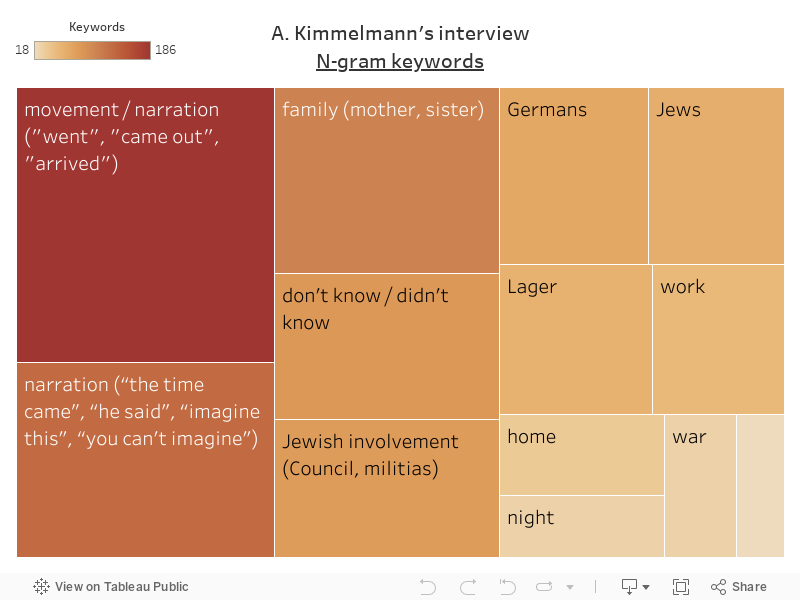
Data source: Voices of the Holocaust (Paul V. Galvin Library, Illinois Institute of Technology).
6. N-gram-based, experimental indexing of Boder’s corpus
Developed by Lizhou Fan and Anna Bonazzi

This visualizations shows a potential index of contents for the German- and English-language interviews in Boder’s corpus. The contents are defined based on the topics indicated by frequent N-grams, manually grouped and labeled into categories. The visualization shows when a certain topic appears in each interview (for example at the beginning, halfway through, at the end). The duration of interviews was normalized by percentage.
Data sources: Voices of the Holocaust (Paul V. Galvin Library, Illinois Institute of Technology) and David Boder, Topical Autobiographies (1957), UCLA Young Research Library Special Collections.
7. Triplets from Kimmelmann’s testimony
Developed by Lizhou Fan and Todd Presner
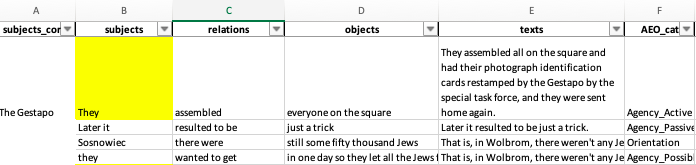
This spreadsheet provides a list of semantic triplets, or subject-relation-object structures, extracted algorithmically from Boder’s interview with Abraham Kimmelmann, to visualize various networks of action and agency that appear in Kimmelmann’s testimony. Built off of SpaCy’s natural language processing methodology, about 2,500 triplets were extracted from Kimmelmann’s 128-page testimony in Topical Autobiographies (translated into English by David Boder). Our algorithm characterized the triplets according to the type of speech employed: active speech, passive speech, coerced actions, speculative speech, evaluations, and orientation. Corrections were made to the outputs in reference to the German original (including pronoun disambiguation and clarification of agents) as well as grammatical correction or completion of the triplets.
Data sources: Voices of the Holocaust (Paul V. Galvin Library, Illinois Institute of Technology) and David Boder, Topical Autobiographies (1957), UCLA Young Research Library Special Collections.