The visualizations below are based on the interviews conducted by David Boder in Displaced Persons (DP) camps in Europe in 1946. Boder recorded the voices of about 120 survivors. His interviews are the first known audio recordings of survivors describing, in their own words, their experiences of the Holocaust and World War II.
Together with his students, Boder also developed the first computational methods to study the interviews attuned to language and trauma. As digital humanists avant la lettre, their archive-building and analytical work represents a key arc for this book. These efforts raise important, humanistic questions at the nexus of quantitative and qualitative analysis, media specificity, early computational linguistics, and trauma theory.
The original recordings can be heard on the Voices of the Holocaust website (Paul V. Galvin Library, Illinois Institute of Technology), along with English translations, introductions, and annotations.
- 1. Change of speakers in Boder’s interviews
- 2. Comparative distribution of question and answer length across four corpora
- 3. Change in languages in Boder’s interviews
- 4. Primary question types in Boder’s interviews
- 5. Analysis of questions in Boder’s corpus
- 6. Spoken word count in Boder’s interviews
- 7. Word count comparisons across corpora
1. Change of speakers in Boder’s interviews
Developed by Lizhou Fan
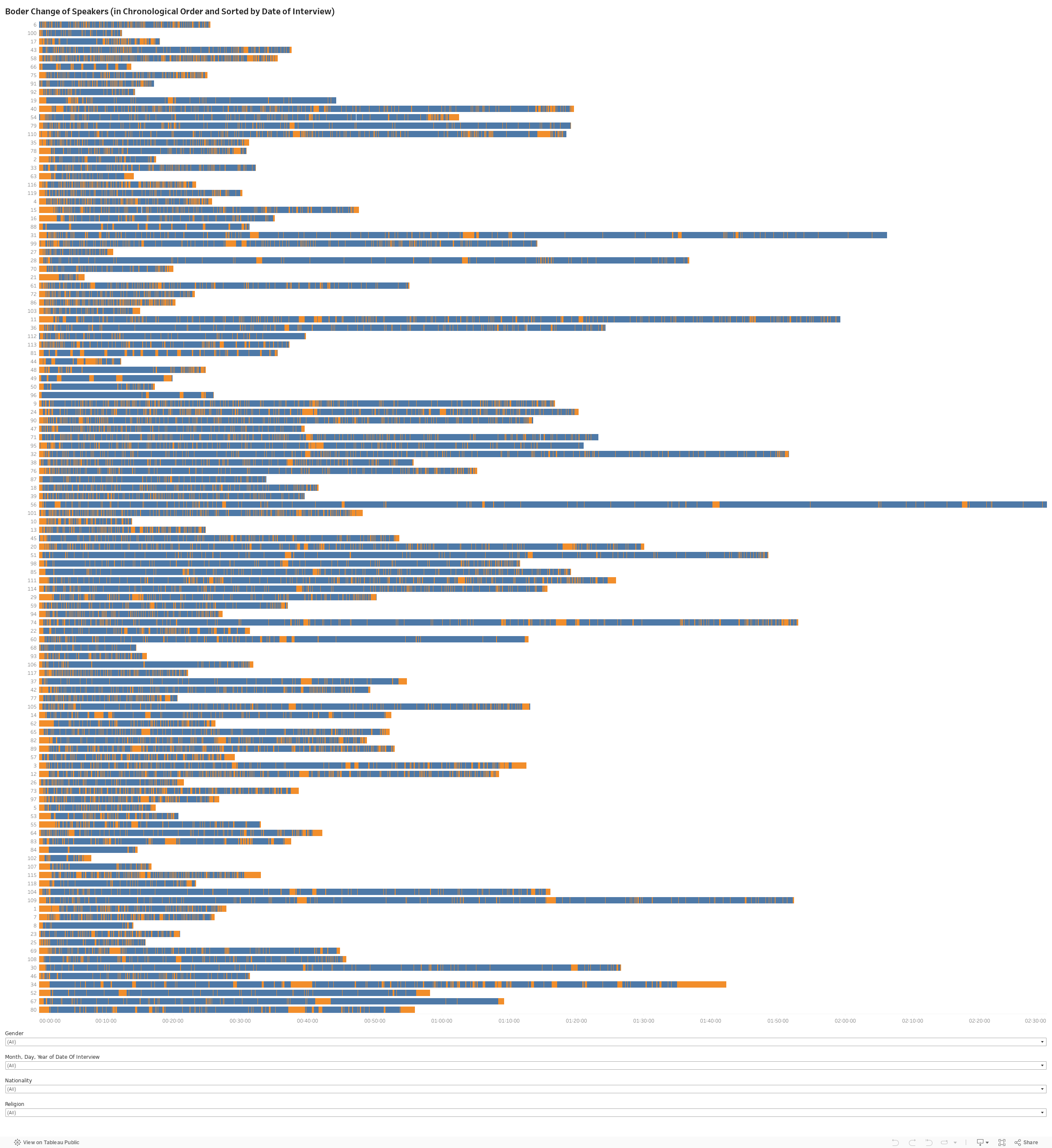
This synoptic visualization shows who is speaking, when, and for how long in Boder’s interviews. Boder is orange, and the interviewee is blue. You can see English translations of the interview when you hover over each segment. The length of the orange and blue bars corresponds to time spoken in the original languages (not to word count).
Data sources: Voices of the Holocaust (Paul V. Galvin Library, Illinois Institute of Technology) and David Boder, Topical Autobiographies (1957), UCLA Young Research Library Special Collections.
2. Comparative distribution of question and answer length across four corpora
Developed by Michelle Lee
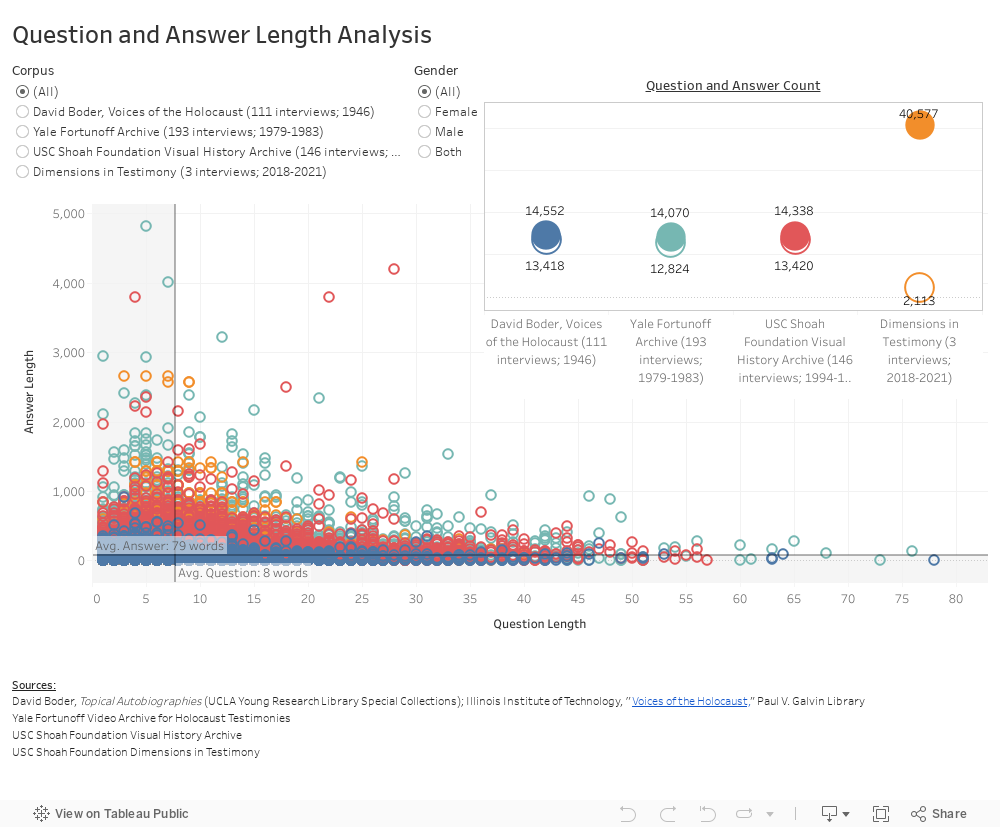
This visualization examines variations in the length of questions and answers from Boder’s corpus (1946) as well as the foundational years of three other corpora: the Yale Fortunoff Archive (1979-1983), the USC Shoah Foundation’s Visual History Archive (1994-1996), and the USC Shoah Foundation’s Dimensions in Testimony project (2018-2021).
3. Change in languages in Boder’s interviews
Developed by Anna Bonazzi and Lizhou Fan
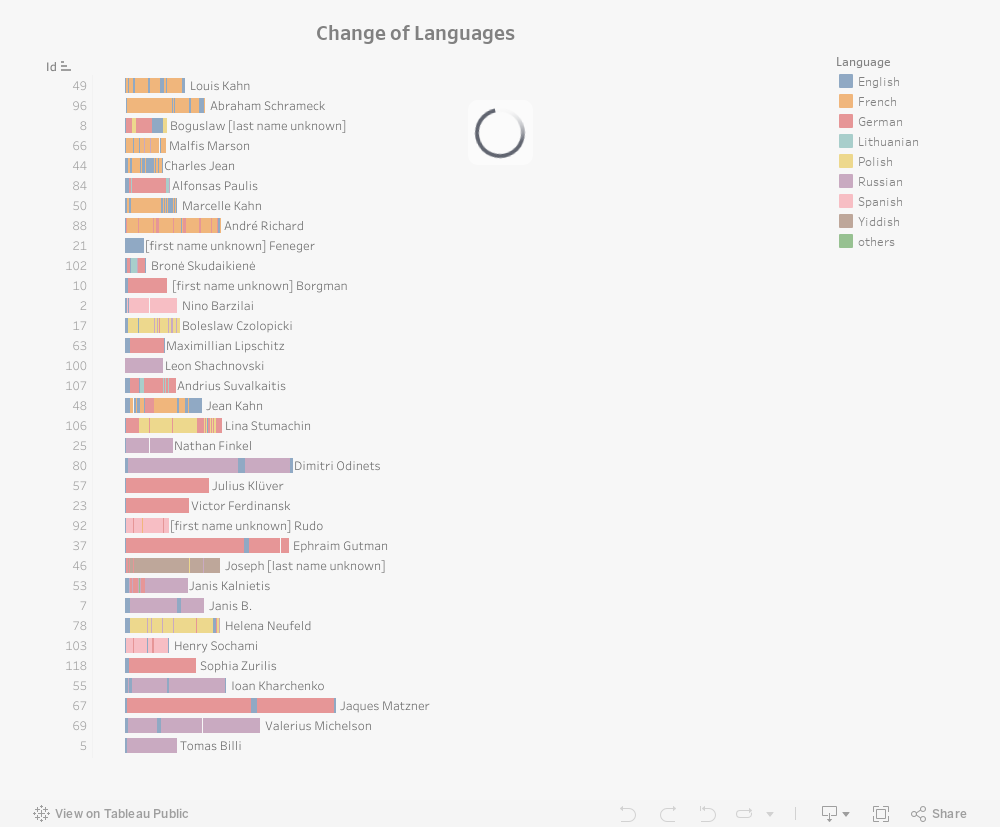
The visualization shows how witnesses switch between different languages over the course of their interviews with David Boder. Interviews are mostly in German, Yiddish, and Polish, but also in Russian, French, English, Lithuanian, Latvian, and Spanish. In some interviews, Boder interviewed in one language (Russian, German, or English) and the interviewee answered in another language (Polish, Yiddish, or French, respectively). Boder’s annotations are mostly in English.
Data sources: Voices of the Holocaust (Paul V. Galvin Library, Illinois Institute of Technology) and David Boder, Topical Autobiographies (1957), UCLA Young Research Library Special Collections. Annotations by Anna Bonazzi.
4. Primary question types in Boder’s interviews
Developed by Lizhou Fan and Todd Presner
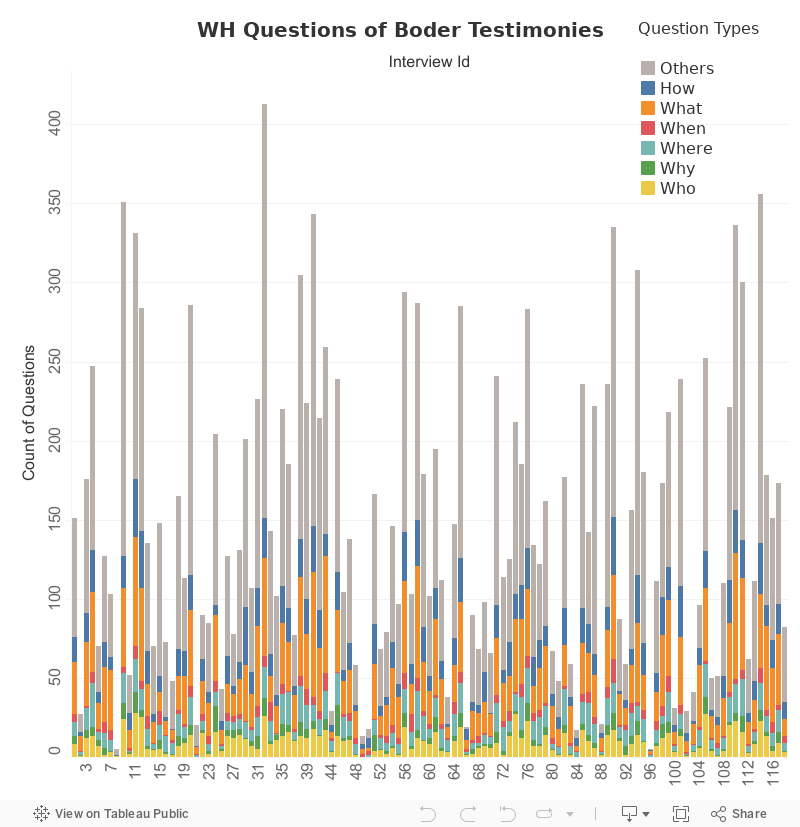
Primary types of questions posed by Boder during his interviews (each column is a different witness, and the metadata spreadsheet can be downloaded above for each interview number). Data sources: Voices of the Holocaust (Paul V. Galvin Library, Illinois Institute of Technology) and David Boder, Topical Autobiographies (1957), UCLA Young Research Library Special Collections.
5. Analysis of 16,360 questions in Boder’s corpus
Developed by Michelle Lee and Todd Presner
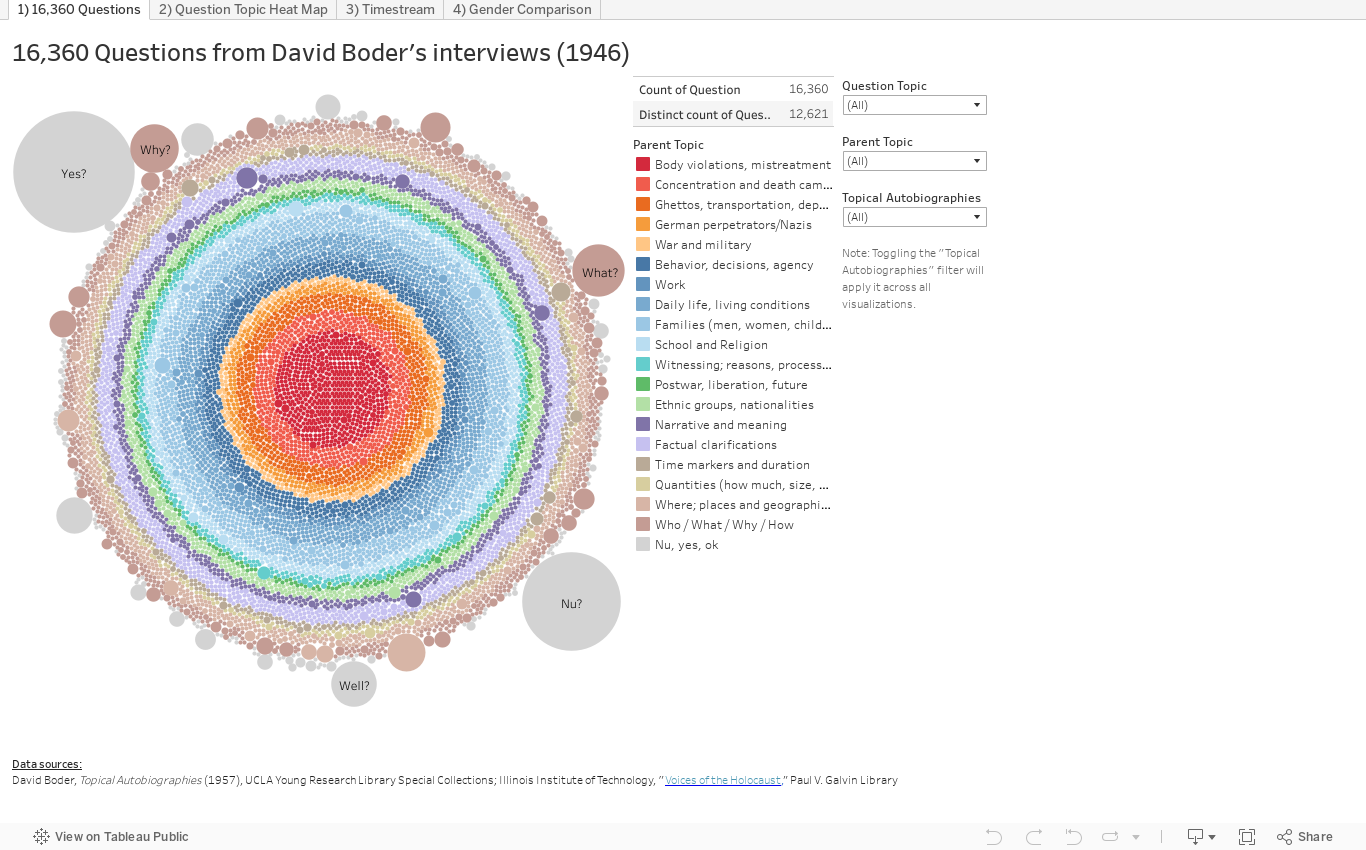
An analysis of 16,360 questions asked by David Boder to 111 survivors clustered by topic. Additional visualizations allow users to explore the number and topics of questions asked to each survivor, view narrative “time streams” of all questions and answers by survivor, and compare the questions asked by Boder to men and women.
6. Spoken word count in Boder’s interviews
Developed by Lizhou Fan
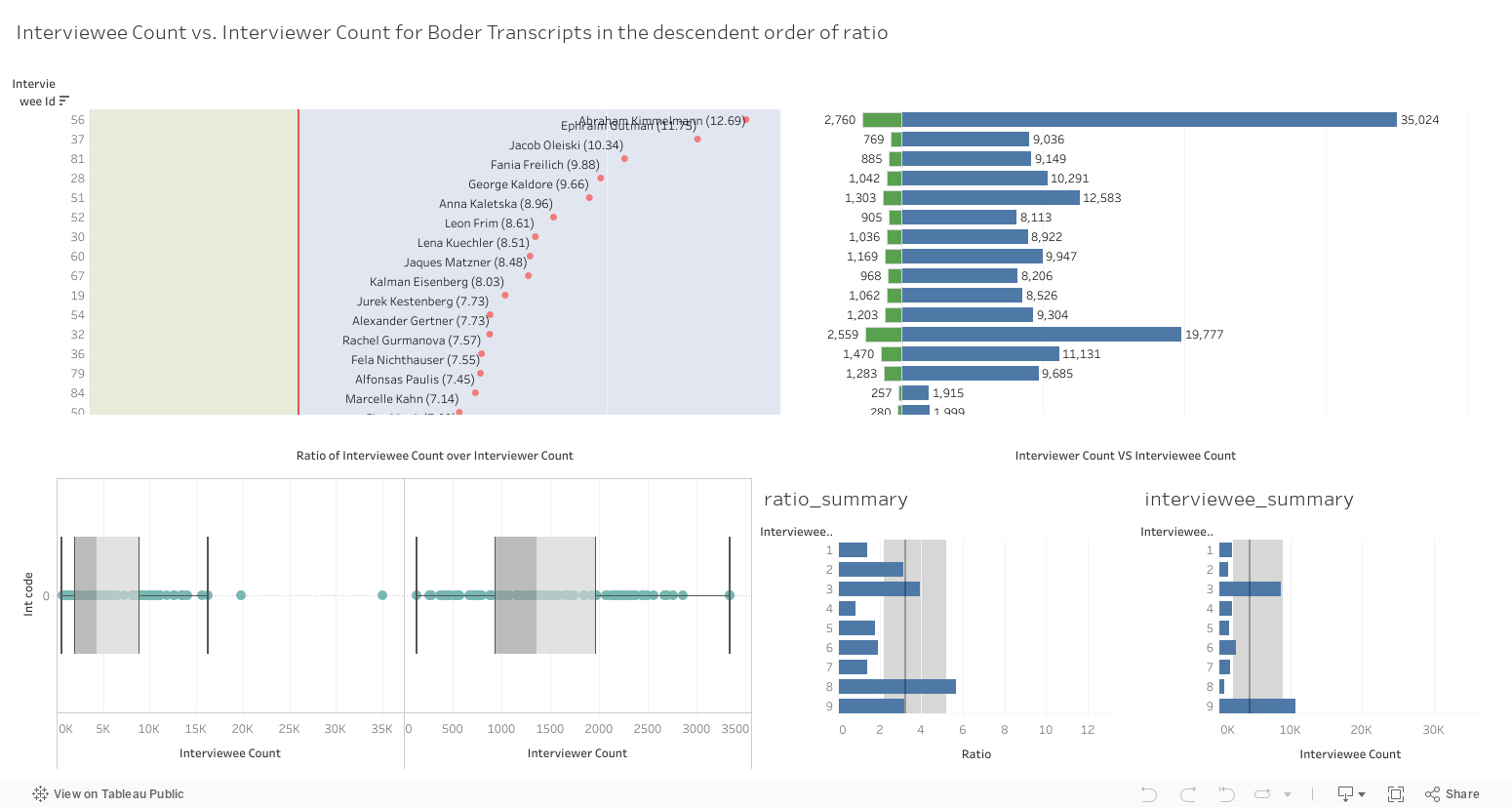
The visualization shows how many words each interviewee spoke during their testimony compared to how many words Boder spoke. Data sources: Voices of the Holocaust (Paul V. Galvin Library, Illinois Institute of Technology) and David Boder, Topical Autobiographies (1957), UCLA Young Research Library Special Collections. The numbers use the English translations for consistency.
7. Word count comparisons across corpora
Developed by Lizhou Fan
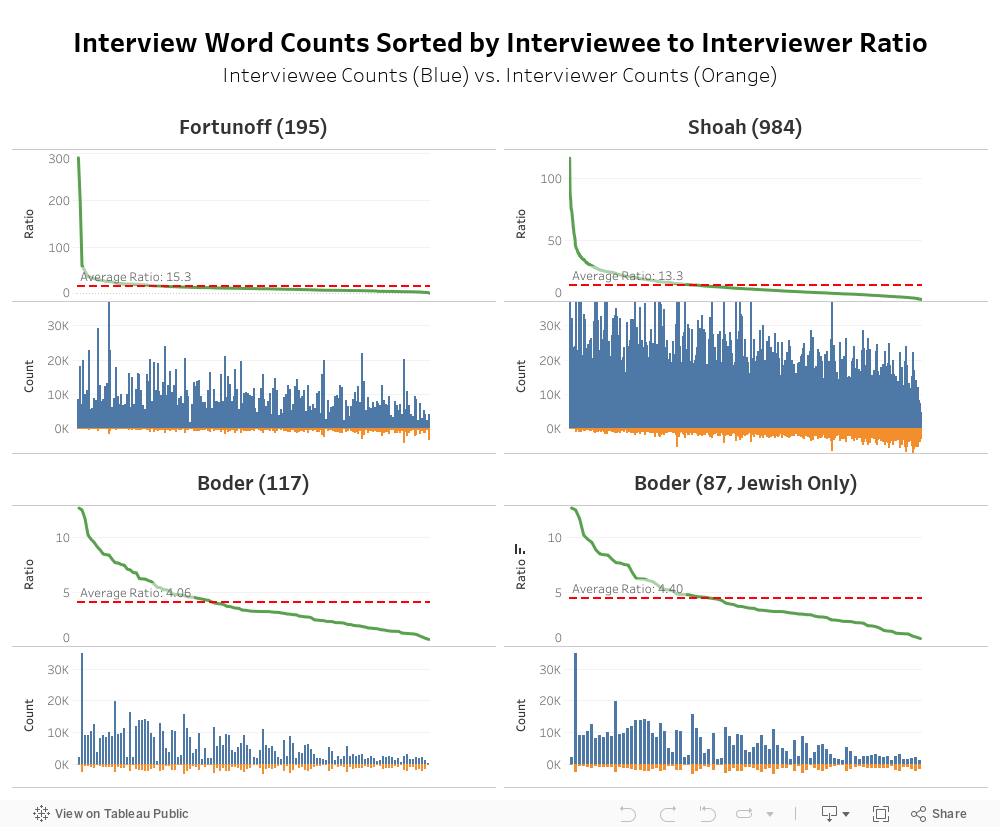
These visualizations compare word counts of interviewee and interviewer across three corpora. In each visualization, the bars along the x-axis represent individual testimonies. Since the number of testimonies differs significantly, the scale for the x-axis is not the same; however, the scale for the y-axis is the same in order to allow accurate comparisons of word counts. All testimonies are in English (or English translations).
Data sources: Voices of the Holocaust (Paul V. Galvin Library, Illinois Institute of Technology); David Boder, Topical Autobiographies (1957), UCLA Young Research Library Special Collections; USC Shoah Foundation Visual History Archive; and Yale Fortunoff Video Archive for Holocaust Testimonies.